
Overview
The Mental Health Sentiment Analysis API is a RESTful API built with ASP.NET Core that classifies user-submitted statements into mental health categories (e.g. Normal, Anxiety, Depression, Stress, Suicidal, etc.). It uses ML.NET to process mental health data and train a multiclass classification model on the data. The API accepts a raw text statement via HTTP and returns the predicted mental health status.
I developed this to demonstrate end-to-end ML model training and deployment using C#, ML.NET and ASP.NET Core. This tool is for demo purposes only and should not be used for real world mental health assessments.
Code and Setup Instructions
| GitHub Repository: | https://github.com/masaki9/MentalHealthSentimentAnalysisAPI |
Features
- Text Cleaning: Custom mapping removes URLs, HTML tags, punctuation, digits, bracketed text, and normalizes to lowercase.
- TF-IDF Featurization: Tokenizes, removes stop-words, maps tokens to keys, then produces TF-IDF weighted n-grams.
- Hyperparameter Sweep: Search over varying L2 regularization strengths with 5-fold cross-validation to find the best multiclass classifier.
- ML Model: Trains and saves the classifier using ML.NET, which is loaded by the RESTful API developed in ASP.NET Core.
- Swagger Integration: Provides comprehensive API documentation and testing capabilities.
Model Performance
I performed hyperparameter tuning over SDCA, LBFGS, OVA + SDCA and OVA + LBFGS across varying L2-regularization strengths. The best cross-validated model was LBFGS with no L2 regularization.
| Best Algorithm | Hyperparameters |
|---|---|
| LBFGS (Maximum Entropy) | No L2 Regularisation |
| Metric | 5-fold CV | Test Set |
|---|---|---|
| Micro Accuracy | 0.7601 | 0.7580 |
| Macro Accuracy | 0.7087 | 0.7059 |
| Log Loss | 1.0966 | 1.1200 |
Summary
Micro Accuracy (overall): 75.8% of all statements are classified correctly.
Macro Accuracy (per-class average): 70.6% macro accuracy means the model’s per-class performance nearly matches its overall score, so minority classes are not neglected.
Log Loss: A log loss of 1.12 is reasonably low for a 7-class problem. It indicates the model is reasonably confident in its predictions.
Model Generalization: The very small gap between cross-validated and test set scores shows the model generalizes well and is not over-fitting.
Technical Details
Implementation
The project follows an MVC architecture and is implemented in C# using ASP.NET Core. The code is organized into the following layers:
- Controller:
- MentalHealthController.cs – Handles incoming HTTP requests and delegates processing to the service layer.
- Service:
- ISentimentAnalysisService.cs – Defines the contract for sentiment analysis operations.
- SentimentAnalysisService.cs – Implements the logic to predict the mental health status based on the given statement.
- Model:
- MentalHealthData.cs – Represents a piece of mental health data including a statement and its corresponding status.
- MentalHealthPrediction.cs – Represents a prediction made by the ML model.
- Application Entry Point:
- Program.cs – Registers the sentiment analysis service as Scoped (one instance per HTTP request), sets up Swagger, and starts the API application.
Architecture Diagram
The following UML diagram illustrates the high-level architecture of the project:
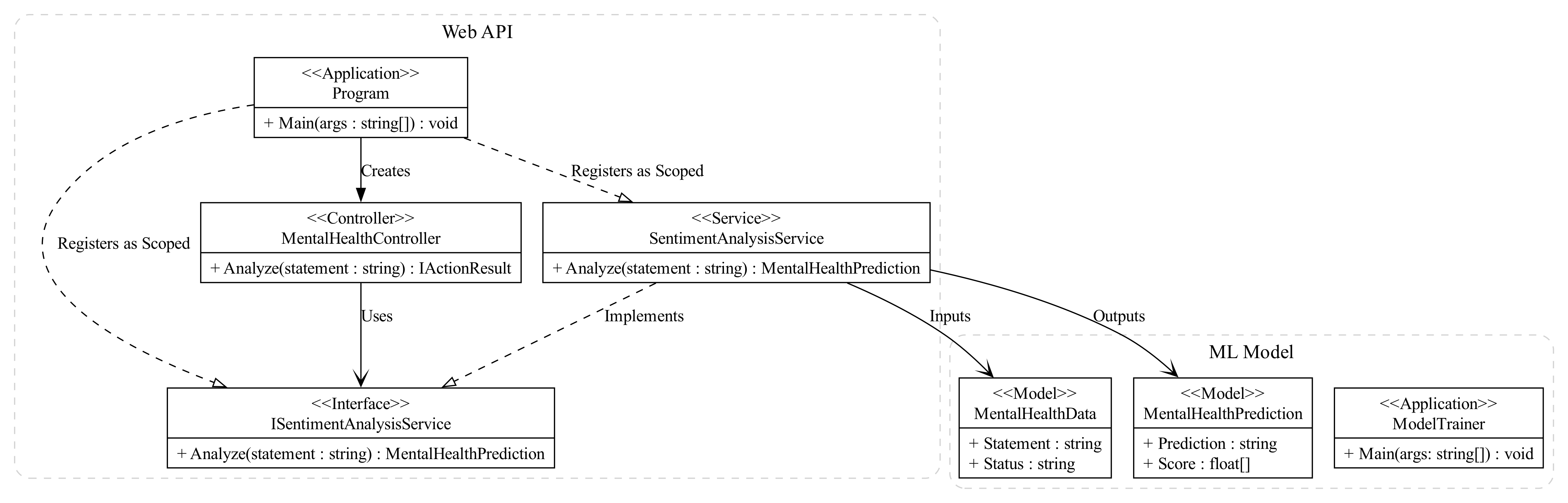 Architecture Diagram
Architecture Diagram
API Documentation
Swagger is integrated to automatically generate interactive API documentation. It enables you to test endpoints directly from your browser.
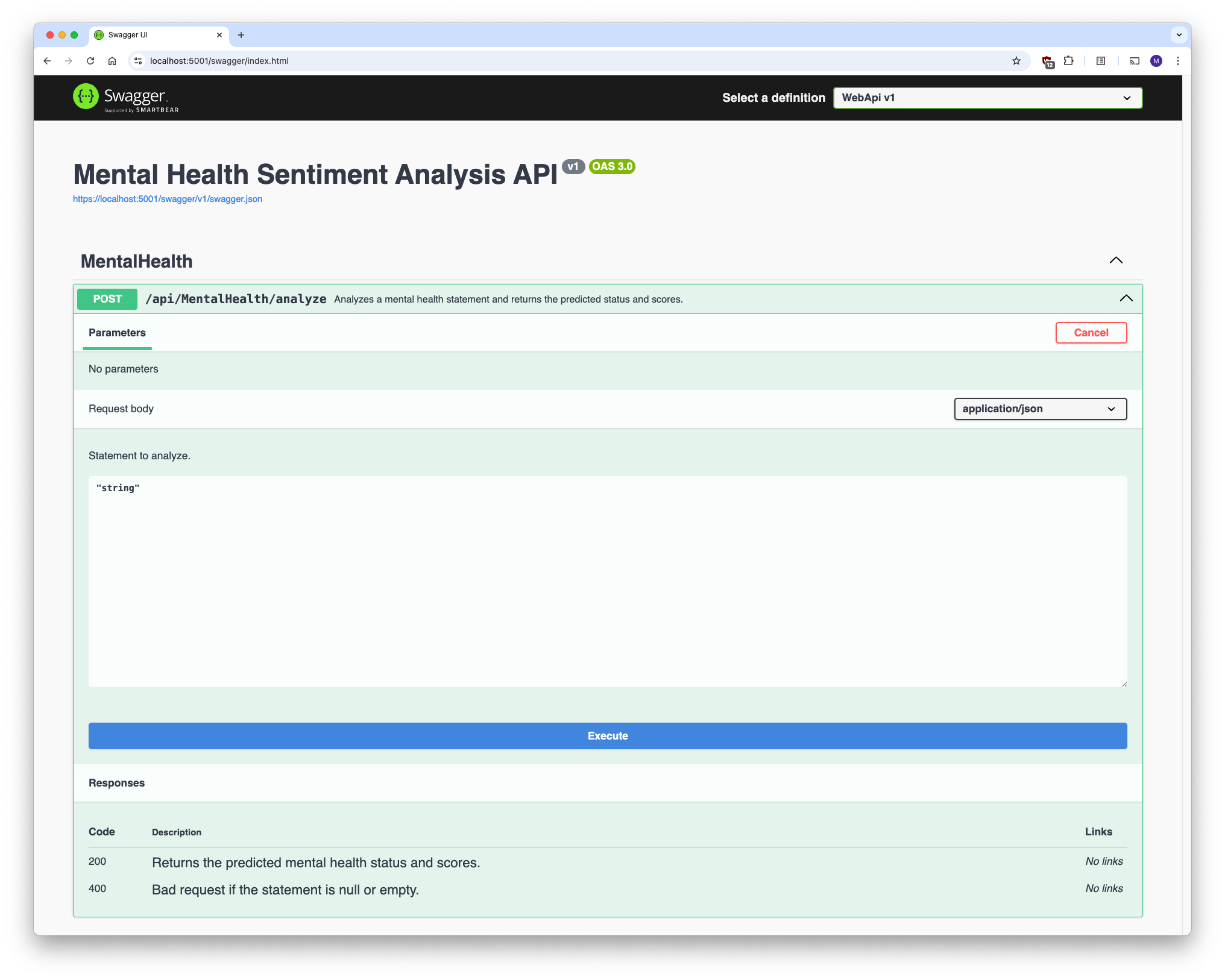 Swagger
Swagger
Conclusion
The Mental Health Sentiment Analysis API demonstrates my ability to develop an end-to-end machine learning solution using C#, ML.NET and ASP.NET Core. This project highlights my object-oriented design skills as well as my understanding of machine learning processes. I have implemented a multiclass classification model to predict mental health categories based on user-submitted statements, which is loaded into a RESTful API. The API accepts a raw text statement via HTTP and returns the predicted mental health status.
For future enhancements, I would look into improve processing data. Due to time constraints, I have not had time to experiment with text processing techniques such as lemmatization and stemming or sampling techniques such as SMOTE, which are unfortunately not built into ML.NET.